GPT-5.5 重磅发布:迈向 AI 智能体的全能新世代
OpenAI 正式发布 GPT-5.5,一款面向 AI 智能体场景的新一代大语言模型。它的核心能力,是完成多阶段、跨工具的复杂任务闭环——从代码编写、Bug 排查,到全网检索、数据分析,再到文档撰写、软件操作,无需人工分步引导,就能自主完成路径规划、工具调用、结果校验,处理需求边界模糊的跨界任务。
这次升级的核心增强,主要集中在智能体编程、设备操作、知识工作与前沿科学研究 4 大领域——这些场景的共性,是对长上下文推理、持续决策与执行能力的极高要求。
行业长期存在一个共识:模型能力的提升,往往伴随推理延迟的增加。但 GPT-5.5 打破了这个规律:在真实服务场景中,它单 Token 输出延迟与 GPT-5.4 完全持平,完成同等难度的 Codex 任务时,Token 消耗量显著下降,实现了能力与效率的同步提升。
| GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro | |
| Terminal-Bench 2.0 | 82.7% | 75.1% | – | – | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | – | – | – | – |
| GDPval (wins or ties) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | – | – | 78.0% | – |
| Toolathlon | 55.6% | 54.6% | – | – | – | 48.8% |
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| CyberGym | 81.8% | 79.0% | – | – | 73.1% | – |
模型核心能力
OpenAI 正在搭建面向 AI 智能体的全球基础设施。过去一年,AI 已经深刻改变了软件工程的工作流;而随着 GPT-5.5 接入 Codex 与 ChatGPT,这种改变正在延伸至科研、日常办公等更多场景。
在这些场景中,GPT-5.5 展现出了更高的问题解决效率——它只需要更低的 Token 消耗与更少的重试次数,就能完成更高质量的任务交付。根据 Artificial Analysis 发布的编码指数,GPT-5.5 以竞品一半的算力成本,实现了当前业内顶尖的编码能力表现。

AI 智能体编程
GPT-5.5 是 OpenAI 目前能力最强的编程模型,并在 3 大主流编程基准上完成了横向测试:
| 测试基准 | 考核维度 | 准确率及表现 |
|---|---|---|
| Terminal-Bench 2.0 | 复杂命令行工作流(需规划、迭代与工具协同) | 82.7% |
| SWE-Bench Pro | 真实 GitHub Issue 解决能力 | 58.6%,单次完成端到端任务 |
| Expert-SWE | 预估耗时超 20 小时的长周期编程任务(内部基准) | 性能全面超越 GPT-5.4 |
三项测试中,GPT-5.5 不仅刷新了前代模型的跑分纪录,还极大降低了完成任务所需的 Token 消耗量。


这种能力在 Codex 场景中得到了充分落地。它可以独立完成代码开发、重构、Bug 调试、测试验证等全栈工程任务。早期测试结果显示,GPT-5.5 能够精准把握大型系统的上下文关联,从模糊的报错信息中定位核心问题,熟练调用工具验证假设,并保证代码改动与现有系统的兼容性。
知识工作与复杂办公
GPT-5.5 基于多步推理的任务处理能力,同样适用于日常办公场景。它能够准确理解用户的核心需求,完成从资料查阅、信息提取、工具调用、结果校验到最终内容输出的全流程工作,将碎片化信息整合为结构化的高价值内容。
在 Codex 环境下,GPT-5.5 在文档撰写、表格制作、幻灯片排版等任务上的表现,显著优于 GPT-5.4。有早期测试用户反馈,无论是运筹学问题求解、财务模型搭建,还是将零散的业务需求转化为结构化方案,GPT-5.5 的完成质量都有代际提升。结合 Codex 的计算机操控能力,GPT-5.5 能够识别屏幕内容、完成鼠标点击与键盘输入,在不同软件的 UI 界面之间自主切换,完成跨应用的复杂操作。
这套能力已经在 OpenAI 内部实现了规模化落地。目前,公司超 85% 的员工每周都会重度使用 Codex,覆盖软件研发、财务审计、公关营销、数据科学、产品管理等多个部门:
公关团队:通过 Codex 分析半年内的演讲邀约数据,搭建了邀约风险评分模型,并验证了一套自动化 Slack 智能体工作流——低风险邀约由 AI 自动回复,高风险邀约则触发人工审核。
财务团队:借助 Codex 完成了 24771 份 K-1 纳税申报表的审核工作,总页数达 71637 页。该工作流实现了个人隐私信息的自动脱敏,相比去年的人工流程,任务周期缩短了两周。
GTM 团队:搭建了周报自动生成工作流,单周可节省 5-10 小时的人工工作量。
在 ChatGPT 端,GPT-5.5 Thinking 实现了更快的响应速度与更精简的答案输出,能够帮助用户高效处理复杂工作;挂载插件后,可完成编程、科研、情报搜集、长文档分析等重度专业任务。
面向高阶用户的 GPT-5.5 Pro,在高难度复杂任务上的完成质量有显著提升,同时保持了极低的推理延迟,可满足严苛的生产力场景需求。测试结果显示,相比 GPT-5.4 Pro,GPT-5.5 Pro 的输出逻辑更严谨、内容更周密、冗余信息更少,在商业分析、法律咨询、教育科研、数据科学等领域的表现尤为突出。
GPT-5.5 在多项知识工作基准测试中取得了行业领先的成绩:
GDPval(横跨 44 个职业的智能体工作规范性测试):84.9%
OSWorld-Verified(独立操作系统真实环境操控考核):78.7%
Tau2-bench Telecom(极限客服工作流测试):无 prompt 微调场景下 98.0%
此外,在 FinanceAgent 基准中取得 60.0%,内部投行建模任务中取得 88.5%,OfficeQA Pro 基准中取得 54.1%



前沿科学研究
前沿科研的核心,是多轮迭代的试错流程:提出假说、搜集证据、验证猜想、解读数据,最终确定下一步研究方向。GPT-5.5 在这类需要长链条推理、持续修正判断的场景中,表现显著优于现有模型。
最具代表性的结果,来自 GeneBench 基准测试——这是一项针对遗传学与定量生物学多阶段复杂数据分析的专项考核,要求模型在近乎零人工干预的前提下,处理含噪声、有歧义的真实科研数据,规避数据干扰项与质控陷阱,最终完成符合统计学规范的分析与结论输出。这类任务通常需要顶尖人类专家数天的工作量,GPT-5.5 在该基准上的表现,相比 GPT-5.4 实现了代际提升。

在面向真实生物信息学场景的 BixBench 基准中,GPT-5.5 也取得了当前已公开模型中的最优成绩。

另一个核心案例是,搭载专属测试组件的 GPT-5.5 内部版本,协助数学家完成了拉姆齐数相关的全新证明。拉姆齐数是组合数学领域的核心研究方向,聚焦图、网络、集合等离散对象的内在规律,相关成果产出难度极高。GPT-5.5 完成了非对角线拉姆齐数长期渐近特性的证明,且该证明在 Lean 环境中通过了完整验证。这意味着,GPT-5.5 不仅能完成代码实现类工作,还能在基础数学领域完成严谨、规范的学术论证。
有 ChatGPT 端的 GPT-5.5 Pro 早期用户反馈,该模型更像一个专业的科研协作伙伴,能够完成手稿打磨、技术论证校验、分析方案推演,同时处理大规模的代码、笔记与 PDF 文献数据,实现了从学术猜想到实验验证的全流程辅助。
模型上线与 API 计费标准
GPT-5.5 现已全面开放给 ChatGPT 与 Codex 的 Plus、Pro、Business、Enterprise 用户;GPT-5.5 Pro 同步向 ChatGPT 的 Pro、Business、Enterprise 用户开放。
ChatGPT 端,Plus 及以上订阅用户现可使用 GPT-5.5 Thinking 模式;面向高难度、高稳定性需求场景的 GPT-5.5 Pro,目前仅对 Pro 及以上订阅用户开放。
开发者端,gpt-5.5将于近期上线 Responses 与 Chat Completions API,具体计费标准如下:
| 模型/计费通道 | Input Token 价格 | Output Token 价格 | 上下文窗口 |
|---|---|---|---|
| gpt-5.5 (标准费率) | $5/1M | $30/1M | 1M |
| gpt-5.5 (Batch/Flex) | 50% 标准费率 | 50% 标准费率 | 1M |
| gpt-5.5 (Priority 优先处理) | 2.5 倍标准费率 | 2.5 倍标准费率 | 1M |
| gpt-5.5-pro | $30/1M | $180/1M | / |
尽管 GPT-5.5 的标准计费单价高于 GPT-5.4,但得益于任务完成效率的提升与 Token 消耗量的下降,绝大多数用户在获得更高质量输出的同时,整体使用成本并不会明显上升。现有各订阅层级的使用配额保持不变。













- 效果远胜 sora 2、veo 3! 字节跳动推出Seedance 2.0 AI视频生成模型
- 魔搭社区成中国最大AI开源社区 已服务全球超2000万开发者
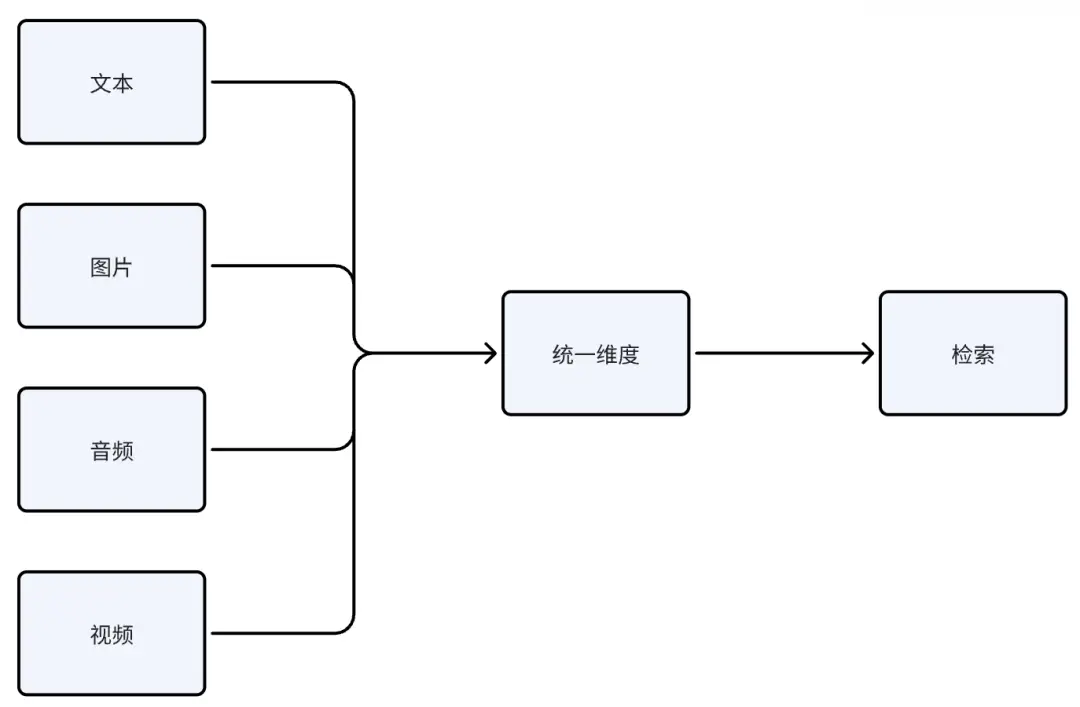
- 多模态检索的实现原理与思路
- 被Anthropic指控侵权,Clawdbot改名Moltbot
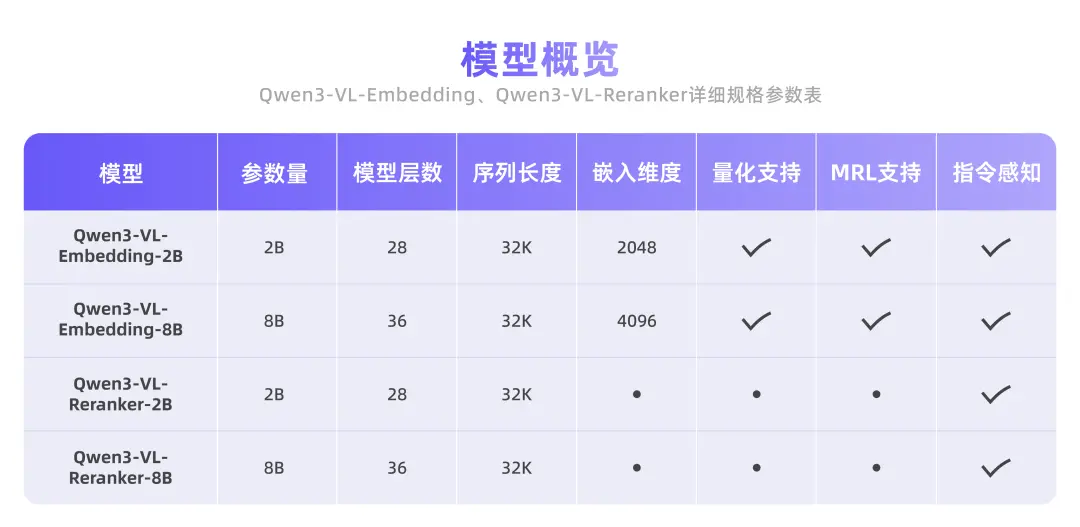
- Qwen3-VL-Embedding & Reranker 开源,专为多模态信息检索与跨模态理解设计
- 史上最贵域名 —— AI.com 网址以 7000 万美元成交
- 人工智能系统如何理解语言和视频
- AI 相关实用工具
- 半年亏掉 80 亿美元后,OpenAI 终于给 ChatGPT 加了广告
- AI圈彻底炸了!Clawbot卷土重来,这次它要取代打工人?
- 五部门发文规范AI拟人化互动服务:不得向未成年人提供虚拟伴侣
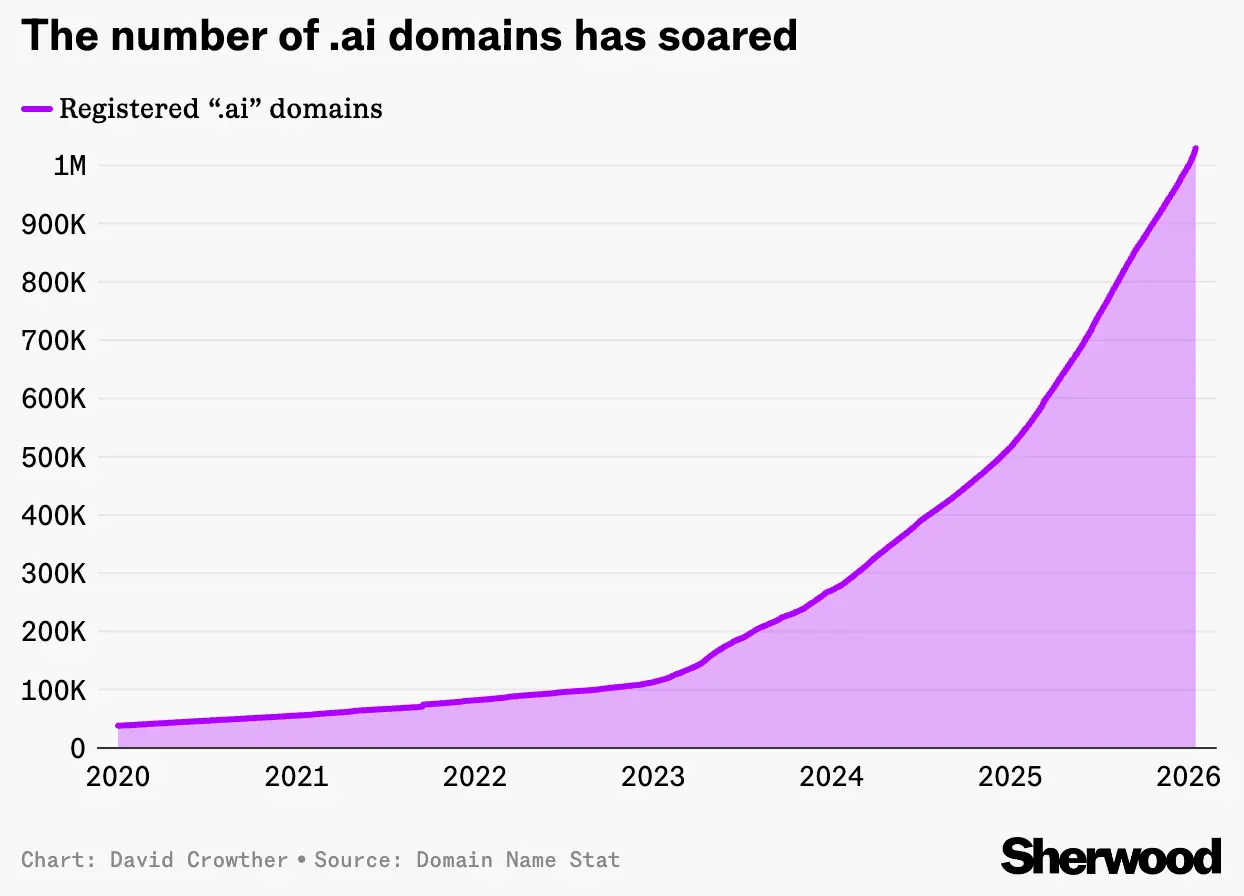
- “.ai” 域名去年为安圭拉政府贡献逾 7000 万美元收入
- 腾讯混元发布混元图像 3.0 图生图模型
- RV1126/RV1109 IPC板 + RK3568+鸿蒙AI视频解决方案
- 智能路由如何实现 90% 成本下降?
- Manifold AI 完成超亿元天使 + 轮融资
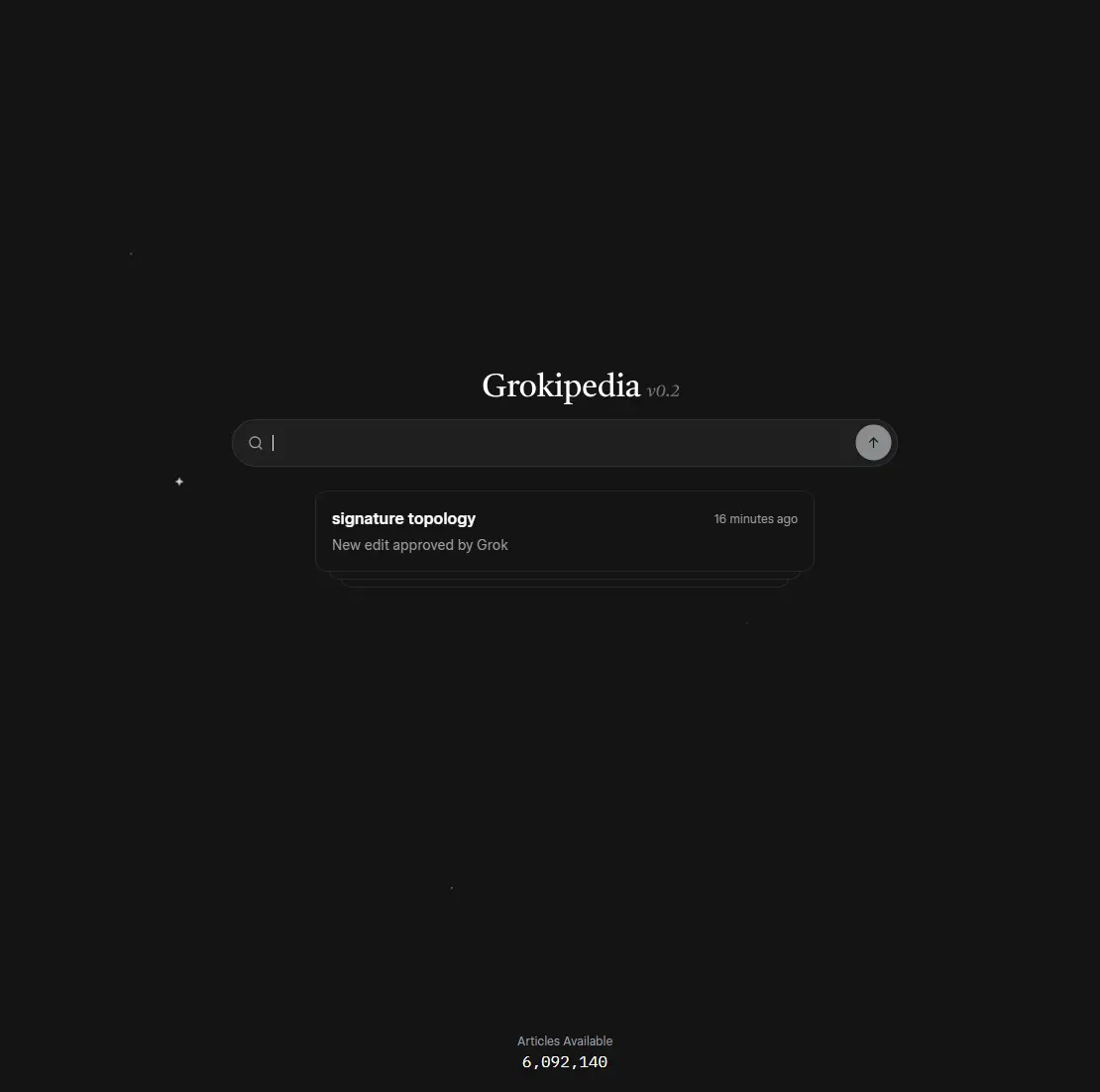
- 马斯克 AI 百科 Grokipedia 条目数突破 600 万,已达英文维基百科 86%
- 6款国产AI视频工具,可以生成10W+爆款短视频
- AI 视频技术全面解析:从基础到实践与未来
- GPT-5.5 重磅发布:迈向 AI 智能体的全能新世代