多模态检索的实现原理与思路
“ 多模态RAG的实现有两种方式,一种是直接表示法,另一种是间接表示法。”
在RAG系统中,需要经过检索召回和生成两个阶段,同样在多模态RAG中亦是如此;在文本RAG中,通过语义相似度可以实现语义检索,但在多模态RAG中,由于涉及到多种模态的数据(文本,图片,视频,音频),因此其并不能直接使用语义检索。
这时怎么实现多模态的数据检索就成了一个难题,因此现在的多模态RAG是怎么解决这个问题的呢?
多模态检索
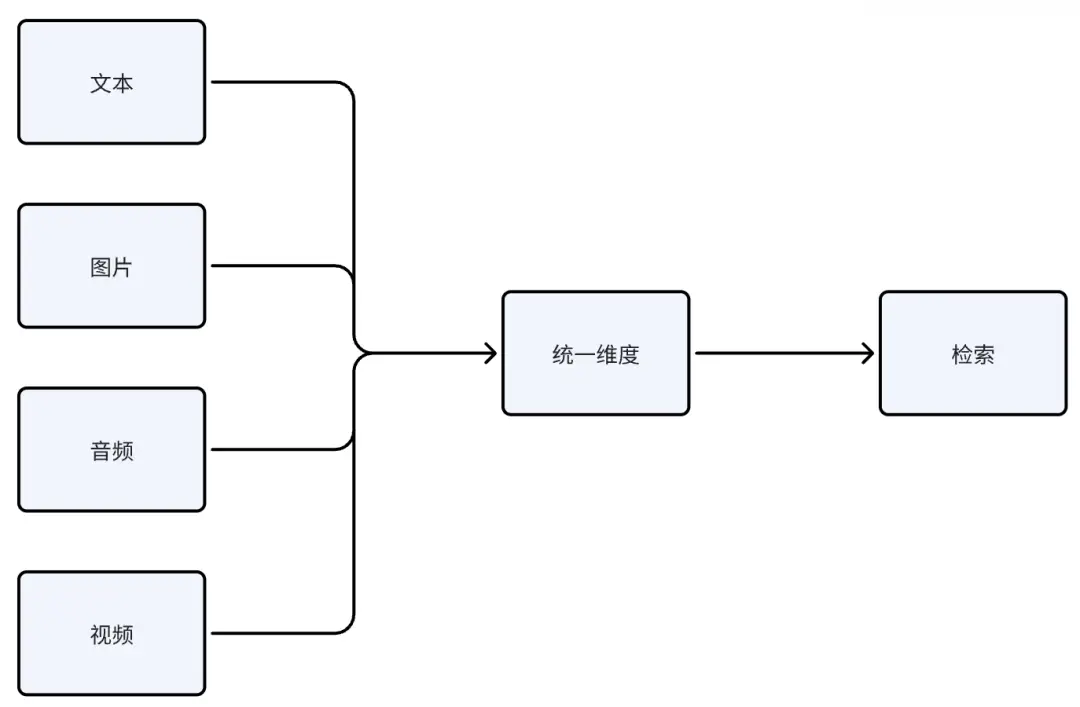
在多模态系统中,由于不同模态的数据存在很大差别,并不能直接用来比较或检索,因此这时就需要一种办法来打破不同模态数据之间的隔阂,让它们能够进行比较与检索。
这玩意就类似于,我无法直接比较一只羊和一袋米,但是我可以通过两者之间的价格进行比较;既然多模态数据的格式不同,所在的维度也不同,那么我们就把它们统一到一个维度里面,这就是多模态检索的实现思路。

在实际的操作过程中,实现这个目的有两种方式,一种是间接表示法,另一种是直接表示法。
所谓的间接表示法,就是用文本模态来表示其它模态的数据;因为文本模态最通用,不论其它任何模态的数据都可以用文本模态来描述。所以,我们可以用文本模态作为中间模态,把其它模态的数据用文本表示之后,再进行相似度检索。
当然,在多模态数据中,不同模态之间的表示可以有多种不同类型的选择;如视频本质上就是动起来的图片,因此视频和图片之间也可以用图片作为中间模态进行检索。音频与文字亦是如此。
其次,就是直接表示法,所谓的直接表示就是把不同模态的数据直接映射到统一向量空间,使得不同模态中语义相似的内容在向量空间中距离最近,其代表作就是openai的Clip多模态模型。
这种方式就是前面所说的,既然大家维度不同,那我们就把大家映射到一个维度上,这样问题就解决了。这也是为什么多模态RAG需要用到专门的Embedding模型。
而要实现这种统一向量空间映射,需要使用多种多模态相关的技术,如多模态表示,多模态融合,跨模态对齐等。

其中,多模态融合又分为三种不同的方式,分别为:
早期融合:将原始数据拼接后输入模型(如RGB-D图像的像素级合并)
中期融合:在特征提取后进行模态对齐(如Transformer的跨模态注意力机制)
晚期融合:对独立模态的预测结果进行决策级融合(如加权投票)
多模态融合能够充分利用不同模态之间的互补性,它将抽取自不同模态的信息整合成一个稳定的多模态表征。
跨模态对齐是通过各种技术手段,实现不同模态数据在特征,语义或表示层面上的匹配与对应。跨模态对齐主要分为两大类:
显示对齐:直接建立不同模态之间的对应关系,包括无监督对齐和监督对齐
隐式对齐:不直接建立对应关系,而是通过模型内部机制隐式地实现跨模态对齐,主要包括注意力对齐和语义对齐。
总之,随着人工智能技术的发展,多模态必定是未来发展的主要方向,但具体怎么实现以及怎么更好的实现多模态,却还是一个值得研究的课题。
本人创建了一个大模型应用学习交流的社群,入群需要缴费19.9,仅此一次不会后续收费,目的是为了防止有人乱发广告,并保持社群的活性;一周内可以免费退群,但乱发广告不退费,并直接踢出。
本文转载自AI探索时代 作者:DFires













- 效果远胜 sora 2、veo 3! 字节跳动推出Seedance 2.0 AI视频生成模型
- AI 相关实用工具
- 魔搭社区成中国最大AI开源社区 已服务全球超2000万开发者
- 多模态检索的实现原理与思路
- 被Anthropic指控侵权,Clawdbot改名Moltbot
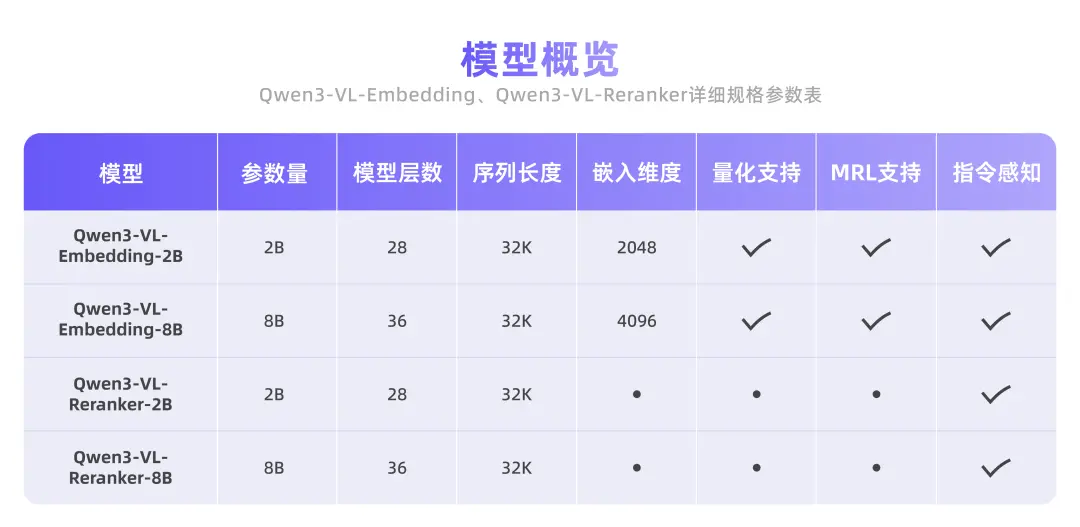
- Qwen3-VL-Embedding & Reranker 开源,专为多模态信息检索与跨模态理解设计
- 史上最贵域名 —— AI.com 网址以 7000 万美元成交
- 人工智能系统如何理解语言和视频
- 半年亏掉 80 亿美元后,OpenAI 终于给 ChatGPT 加了广告
- AI圈彻底炸了!Clawbot卷土重来,这次它要取代打工人?
- 五部门发文规范AI拟人化互动服务:不得向未成年人提供虚拟伴侣
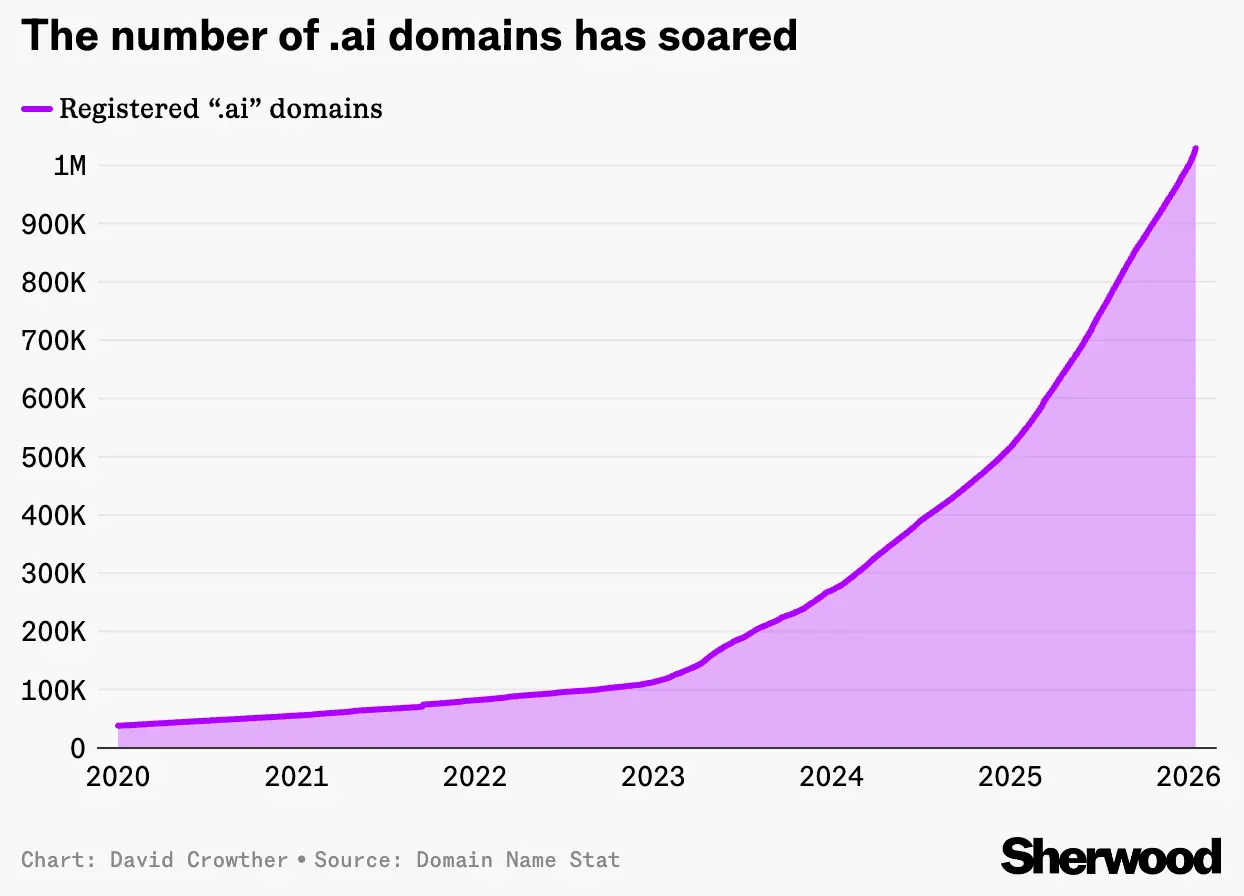
- “.ai” 域名去年为安圭拉政府贡献逾 7000 万美元收入
- 腾讯混元发布混元图像 3.0 图生图模型
- RV1126/RV1109 IPC板 + RK3568+鸿蒙AI视频解决方案
- 智能路由如何实现 90% 成本下降?
- Manifold AI 完成超亿元天使 + 轮融资
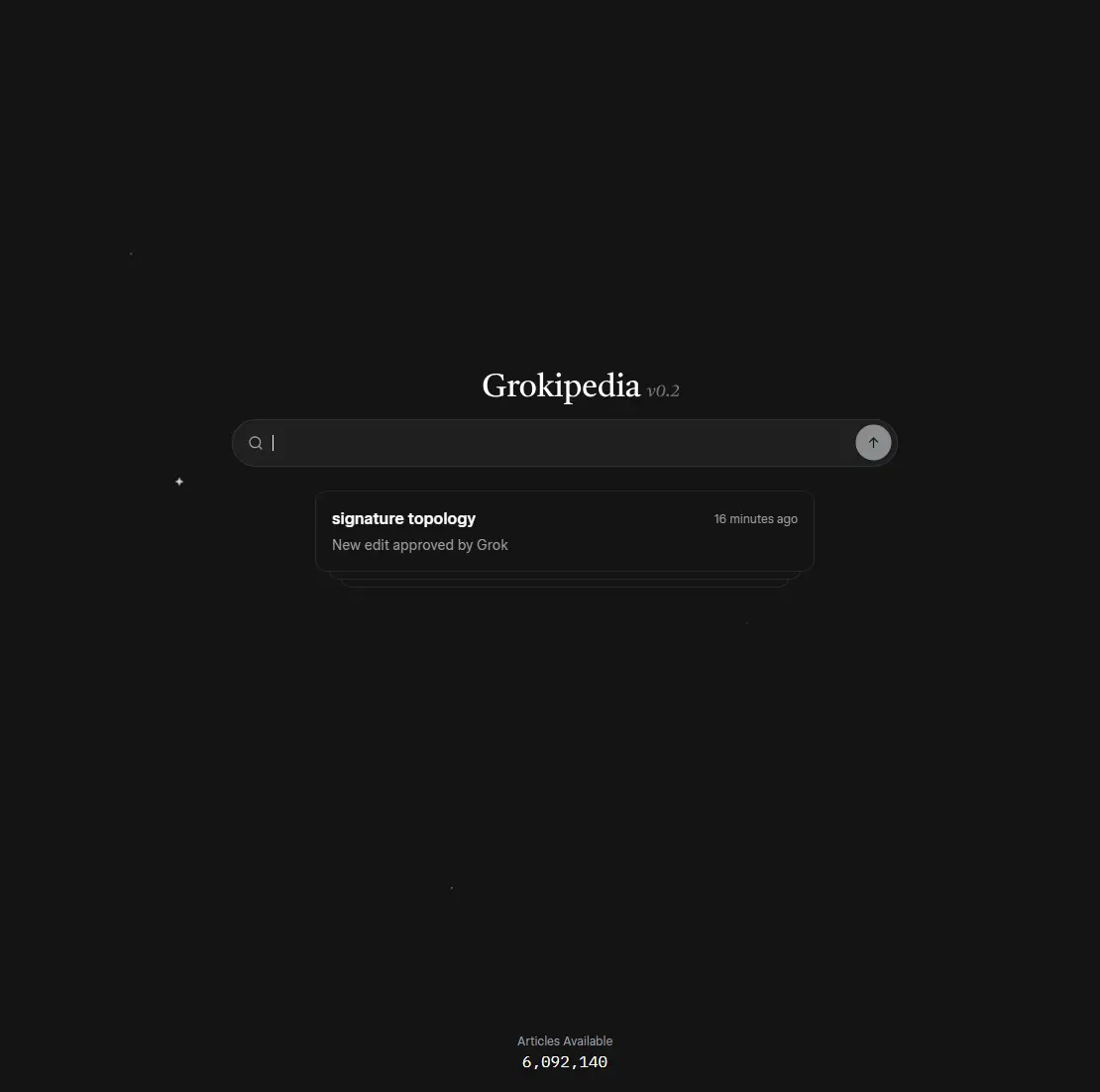
- 马斯克 AI 百科 Grokipedia 条目数突破 600 万,已达英文维基百科 86%
- 6款国产AI视频工具,可以生成10W+爆款短视频
- AI 视频技术全面解析:从基础到实践与未来
- GPT-5.5 重磅发布:迈向 AI 智能体的全能新世代