OpenAI 用 PostgreSQL 扛起 8 亿用户级别流量
OpenAI 发布最新技术博客,披露了其如何将开源关系型数据库 PostgreSQL 扩展到前所未有的规模,以支撑 ChatGPT 和 API 的全球业务,这一实践刷新了业内对传统数据库可扩展性的认知。
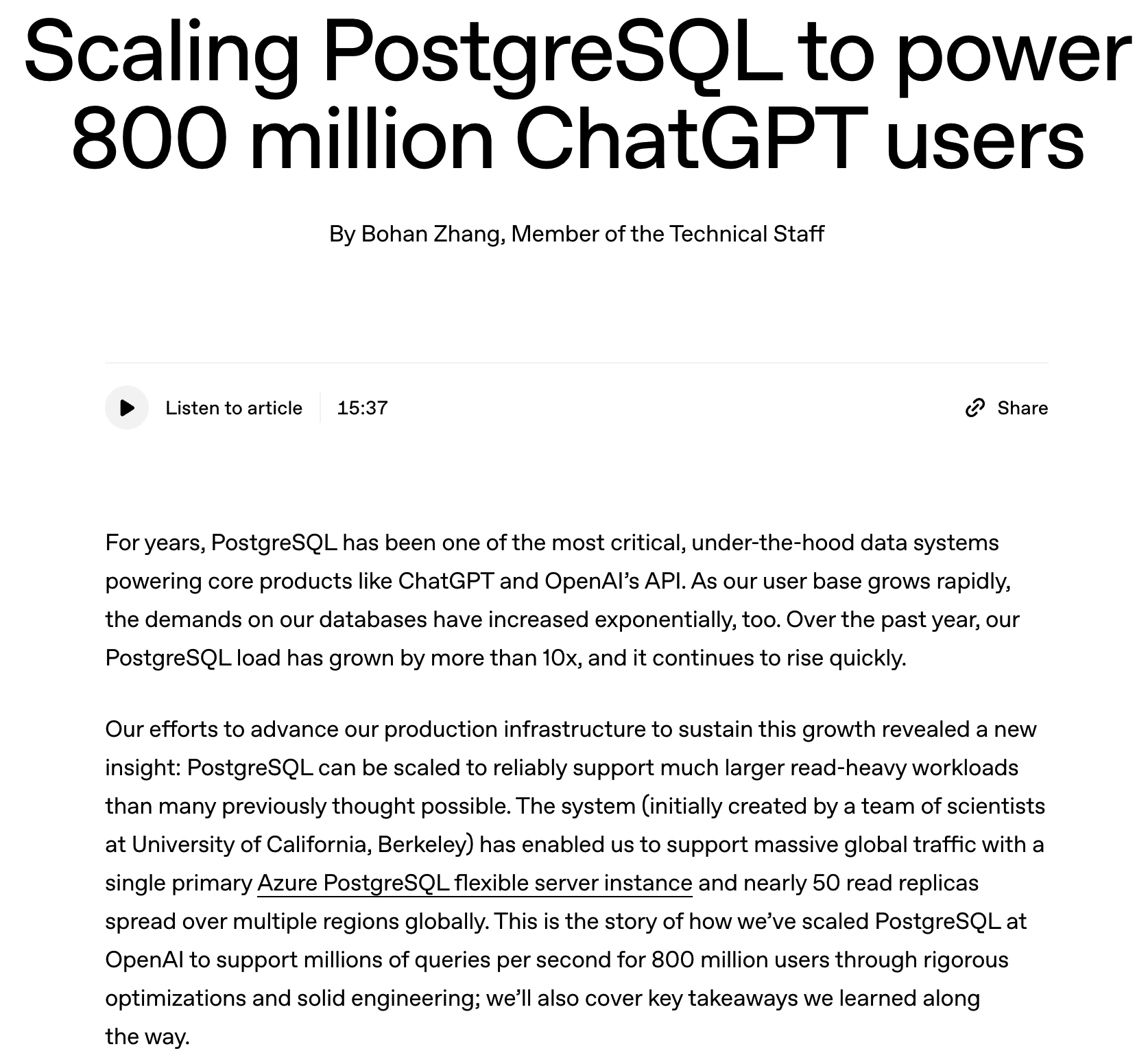
随着 ChatGPT 用户数快速增长,OpenAI 过去一年里 PostgreSQL 的数据库负载激增超过 10 倍。为了满足数百万级查询 / 秒(QPS)的请求并保持低延迟性能,他们在架构上进行了大量优化。
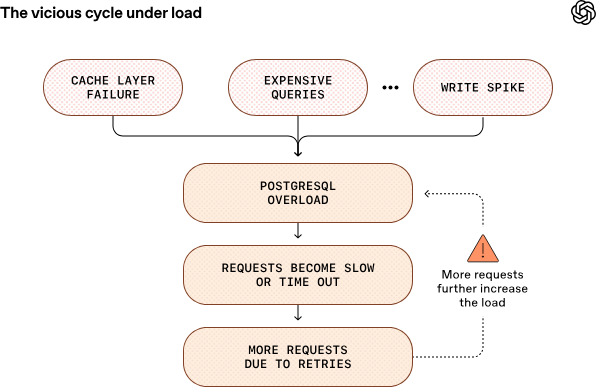
核心架构依旧采用单主库(single-primary) + 多只读副本方案,主库负责写入工作,约 50 个只读副本分布全球多个区域用来处理读取请求。这样既避免了复杂的分片系统,又能支持大规模读负载。
核心优化策略
1. 分离读写,并减少写入压力
为了防止主库写入瓶颈,OpenAI 将可拆分的写密集型工作负载迁移到分片系统(如 Azure Cosmos DB),并在应用逻辑层尽量减少不必要的写操作。
2. 读查询尽可能下放到副本
主库仅保留必须在写事务中运行的查询,其他读取由全球副本处理,大幅减少主节点负载。
3. 连接池与缓存策略
使用 PgBouncer 做连接池代理,把数据库连接延迟从约 50ms 降到 5ms,并结合高效缓存策略避免缓存雪崩事件引发数据库突发压力。
4. 限制复杂查询与优先级隔离
避免资源密集型的多表 JOIN,必要时将复杂逻辑移到应用层。使用资源隔离机制,将低优先级请求隔离到单独实例,防止 “吵闹邻居” 影响高优先级流量。
5. 高可用性与故障缓解
主库采用高可用 HA 模式,并配有热备实例,在故障时能快速切换,保障服务连续性。
经过这些系统性优化,OpenAI 的 PostgreSQL 设计达成了:
几百万 QPS 的读性能
全球低延迟访问
99.999% 可靠性
极低的 p99 延迟(十几毫秒级)
在过去 12 个月里,只有一次严重数据库级事件(SEV-0),发生在 ImageGen 功能爆发式增长时。
OpenAI 的案例表明,传统的 PostgreSQL 在强工程实践与架构优化下,能够支持极大规模的生产级负载,这对于很多没有充分理由提前采用复杂分布式数据库的团队来说,具有重要的参考价值。
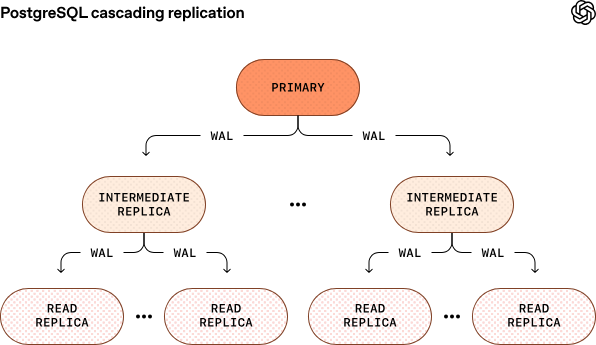
未来 OpenAI 也在探索更进一步的方案,例如 PostgreSQL 的分片或级联复制等,以支撑更大规模的读副本扩展需求。





- MySQL的视图起什么作用?
- MySQL的触发器主要解决什么问题?
- MySQL如何完成数据类型的转换?
- MySQL存储过程和存储函数的区别是什么?
- MySQL锁机制详解:优化数据库并发访问
- MySQL 通过 Next-Key Locking 技术(行锁+间隙锁)避免幻读问题
- 一文彻底弄懂mysql的事务日志,undo log 和 redo log
- MySQL中的redo log、undo log、binlog是什么,作用和区别是什么
- Mysql的WAL技术
- MongoDB中如何使用JavaScript函数?
- 【数据仓库作业】第1章 绪论
- 一文彻底弄懂MySQL的优化
- 一文彻底弄懂MySQL的各个存储引擎,InnoDB、MyISAM、Memory、CSV、Archive、Merge、Federated、NDB
- MySQL 用户管理命令详解:如何修改用户密码、权限和主机
- 一次彻底讲清如何处理mysql 的死锁问题
- 一文彻底搞透Redis的数据类型及具体的应用场景
- MySQL的truncate和delete的区别是什么?
- 什么是MySQL中的全文检索?
- 压缩率提升 48%,详解 Apache Doris 存储压缩优化之道|Deep Dive
- 一文彻底弄清Redis的布隆过滤器