智谱联合华为开源首个国产芯片训练的多模态 SOTA 模型
智谱宣布联合华为开源新一代图像生成模型 GLM-Image,模型基于昇腾 Atlas 800T A2 设备和昇思 MindSpore AI 框架完成从数据到训练的全流程,是首个在国产芯片上完成全程训练的 SOTA 多模态模型。
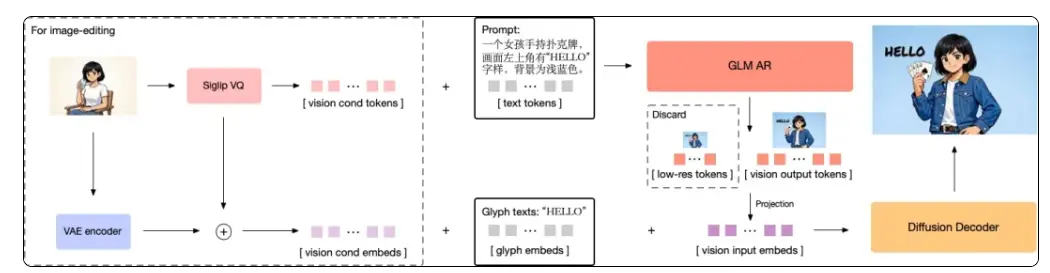
根据介绍,GLM-Image 采用自主创新的「自回归 + 扩散解码器」混合架构,实现了图像生成与语言模型的联合,是我们面向以 Nano Banana Pro 为代表的新一代「认知型生成」技术范式的一次重要探索。
核心亮点如下:
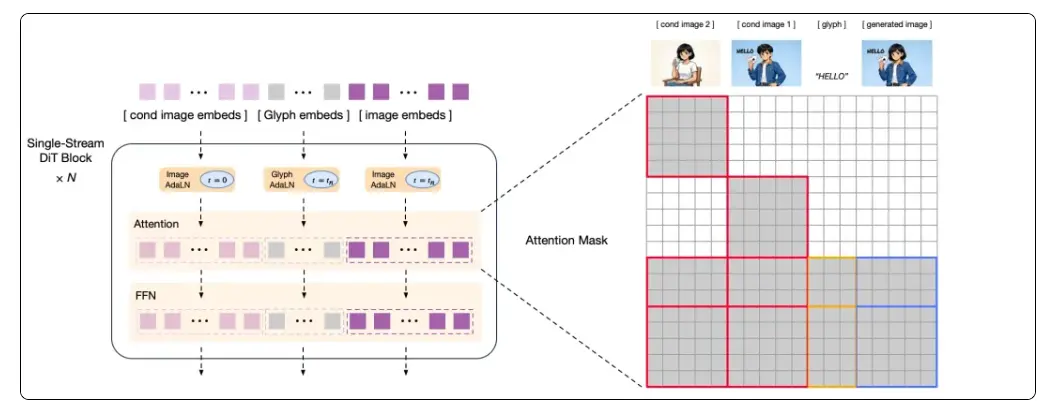
架构革新,面向「认知型生成」的技术探索:采用创新的「自回归 + 扩散编码器」混合架构,兼顾全局指令理解与局部细节刻画,克服了海报、PPT、科普图等知识密集型场景生成难题,向探索以 Nano Banana Pro 为代表的新一代 “知识 + 推理” 的认知型生成模型迈出了重要一步。
首个在国产芯片完成全程训练的 SOTA 模型:模型自回归结构基座基于昇腾 Atlas 800T A2 设备与昇思 MindSpore AI 框架,完成了从数据预处理到大规模训练的全流程构建,验证了在国产全栈算力底座上训练前沿模型的可行性。
文字渲染开源 SOTA:在 CVTG-2K(复杂视觉文本生成)和 LongText-Bench(长文本渲染)榜单获得开源第一,尤其擅长汉字生成任务。
高性价比与速度优化:API 调用模式下,生成一张图片仅需 0.1 元,速度优化版本即将更新。
评测结果显示,GLM-Image 在文字渲染的权威榜单中达到开源 SOTA 水平。
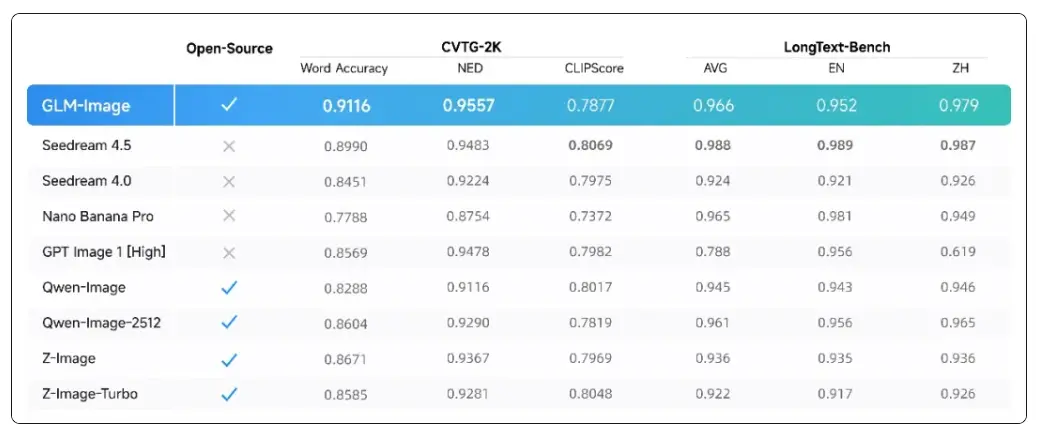
CVTG-2K(复杂视觉文字生成)榜单核心考察模型在图像中同时生成多处文字的准确性。在多区域文字生成准确率上,GLM-Image 凭借 0.9116 的 Word Accuracy(文字准确率)成绩,位列开源模型第一。在 NED(归一化编辑距离)指标上,GLM-Image 同样以 0.9557 领先,表明其生成的文字与目标文字高度一致,错字、漏字情况更少。
LongText-Bench(长文本渲染)榜单考察模型渲染长文本、多行文字的准确性,覆盖招牌、海报、PPT、对话框等 8 种文字密集场景,并分设中英双语测试,GLM-Image 以英文 0.952、中文 0.979 的成绩位列开源模型第一。
















- 酷态科 10 号 - 超级电能棒特别版充电宝上架:10000mAh 容量 + 150W 功率,249 元
- 骁龙顶级处理器来了!拳打苹果,脚踢天玑
- 数据治理之数据架构:定义、方法和职责
- 开不起的网约车:头顶四座扣分大山,每天跑15个小时、月净赚两三千
- 谷歌联合创始人布林重回公司,参与研发新一代AI系统
- 英伟达黄仁勋与亚洲首富合作打造Blackwell AI数据中心
- 在 Excel 中如何制作同比分析柱形图
- 高通连甩座舱智驾双芯 12倍AI性能暴涨!奔驰理想将搭载
- 抖音电商:2023 年商城 GMV 同比增长 277%,884 万作者获得收入
- 我国互联网用户规模持续扩大 产业发展稳步增长
- 全球半导体产业走向碎片化,中国如何扬长避短掌握主动权?
- 谷歌正在为 Android 系统开发 “时间轴定位” 功能
- 微软开源基于 Rust 的 OpenHCL
- ChatGPT 登陆 Windows
- 苹果中国上线迎新春限时活动:iPhone 15 系列手机最高降 500 元,Mac、iPad 也有优惠
- 字节跳动技术副总裁洪定坤:TRAE 想做 AI Development
- 比英伟达有潜力,摩根大通逆势唱多:亚洲芯片股涨势将追上美国芯片股
- 字节跳动商业化团队模型训练被 “投毒”,内部人士称未影响豆包大模型
- LG 电子宣布 LG UltraGear evo 高分辨率电竞显示器产品线
- VMware Workstation Pro 25H2u1 发布
- 研究:广播公司围绕 IP 重建直播运营
- Orange Business 发布人工智能、协作和语音创新技术
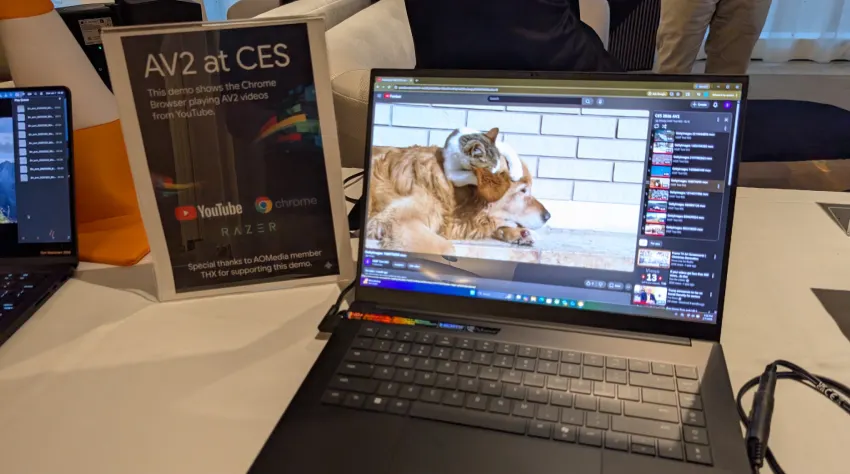
- 在消费级笔记本电脑上演示实时 AV2 解码
- 九号率先接入 OpenClaw,AI Agent 开始走进两轮智能电动车
- VMware Workstation Pro 25H2u1 发布
- 用好AI的七个层次:90%的人卡在第三层,你在哪一层?
- 微软 Win11/10/7 原版 ISO 光盘镜像下载大全(2026-2-10 更新)
- 用禅道,让AI成为更懂你的项目专家!
- jQuery 在 20 岁生日之际,jQuery 4.0 终于发布正式版本了
- Opera One 浏览器发布 R3 更新,重构 AI 底层、优化智能 AI 体验